Friday 16 December 2016
Movie stars
Our search for potential alternatives to an academic career, in the face of increasing competition and difficulties in securing grant money has now led Jolene, Marcos and me to seek employment in the show-biz $-$ just in case we fail to recruit enough students for our new MSc in Health Economics & Decision Science...
Thursday 15 December 2016
PhD opportunity!

The requirement for admission to the MPhil/PhD in Statistical Science is a 1st class or high upper 2nd class Bachelor’s degree, or a Master’s degree with merit or distinction, in Mathematics, Statistics, Computer Science, or a related quantitative discipline. Overseas qualifications of an equivalent standard are also acceptable. Further details can be found on the Departmental website. Applicants are expected to prepare an outline proposal of their work. We have some interesting project in our pipeline, including extensions of our work on survHE, or related to evidence synthesis and network meta-analysis, as well as the use of observational data for health economic evaluation.
The studentship will be four years in duration and covers tuition fees at the UK/EU rate plus a stipend of £16,785 per annum for eligible UK residents. EU nationals who have not been ordinarily resident in the UK for 3 years prior to the start of the studentship may still qualify for a fees only award. The studentship may only be awarded to applicants liable to pay tuition fees at the UK/EU rate (i.e. it cannot be used to part-cover overseas tuition fees).
Further information, including details of how to apply, is available here.
Bayes 2017

The format is the same as in the past few years $-$ you can send your abstract (including title, authors and not exceeding 300 words) at info@bayes-pharma.org. We're pretty much open to many research areas, as long as they involve Bayesian statistics (I feel I have to say this $-$ in the past we had invariably at least a couple of abstracts that had absolutely nothing to do with a Bayesian analysis!...).
Friday 9 December 2016
Nomen omen

In both cases, while I think the packages do work nicely, I am still not sure they are ready for an official release on CRAN $-$ effectively, this is mainly due to the fact that documentation may not be super yet, or, more importantly, that I'm still updating some of the basic functions a bit too often.
I knew GitHub was the way to go, but like a grumpy old man I've so far resisted the idea of learning how to manage it. However, because people I wanted to test survHE were struggling to install it (because of its complicated system of dependencies $-$ I'll say a bit more later), I thought this will be a very good alternative.
So, I've created Git repositories for survHE and SWSamp (I've talked about this here) and the packages can be installed by using devtools in R $-$ I think something like this:
install.package("devtools")
install_github("giabaio/survHE")
install_github("giabaio/SWSamp")
I think devtools may fail to install all the dependencies' dependencies under Windows (as far as I understand this is a bug that will be fixed soon) $-$ so the workaround is to use the development version of devtools. Or indulge R and install the missing packages that it requires.
Friday 2 December 2016
Good stuff around

Anyway, I know of at least a couple of very interesting events:
1) Petros' course on Decision modeling using R, in Toronto, in February 2017. Last year he kindly invited me and I gave some sort of BCEA tutorial, which I really enjoyed.
2) Emmanuel's summer school on advanced Bayesian methods, in Leuven, in September 2017 (I think their website is not live yet, but info will be available at the i-Biostat website). I think they'll do a three-day course on non-parametric Bayesian methods and then a two-day course on Bayesian clinical trials.
Wednesday 23 November 2016
Come & play with us!
We're starting to build up the promotional material for our new MSc in Health Economics and Decision Science. Here's the first of a few videos we've filmed!
Monday 21 November 2016
Summer School: Bayesian Methods in Health Economics

The five of us have decided we should take these to the next level and so have arranged to merge the two programmes and enjoy a well in late Spring next year in Florence. Now, you may think I'm massively biased (because Florence is my home town) $-$ and partly I am $-$ but the place we chose and managed to book is really awesome.
The programme of the lectures in the summer school is the following:
- Introduction to health economic evaluations
- Introduction to Bayesian inference
- Introduction to Markov Chain Monte Carlo in BUGS
- Cost and cost-utility data
- Statistical cost-effectiveness analysis
- Probabilistic sensitivity analysis (PSA)
- Advanced topics in PSA
- Model error and structural uncertainty
- Evidence synthesis (1) - hierarchical models
- Evidence synthesis (2) - network meta-analysis
- Markov models
- Introduction to the theory of the value of information
- Expected value of partial information (1) - theory & algebraic tricks
- Expected value of partial information (2) - nested Monte Carlo
- Expected value of partial information (3) - generalised additive models & GP regression
- Expected value of partial information (4) - GP regression via integrated nested Laplace approximation
- Expected value of sample information (1) - conjugated analysis
- Expected value of sample information (2) - regression-based methods
We have planned for a maximum of 30 participants $-$ in previous editions, we've had most people coming from the UK. This time we're hoping for an "inverse-Brexit" to branch out more widely to other European countries. Participants will all be able to stay at the Centro Study (there are 10 single and 10 double rooms available, so book quickly if you definitely want a single!).
The registration fee also includes a copy of the three main books used as reference in the course: BMHE, The BUGS Book and Evidence Synthesis for Decision Making in Healthcare. We'll also prepare a full set of handouts and computer code (R and BUGS) that we use in the practicals.
Registration is already available (from now to the end of April) on the UCL Store. We offer a lower rate for students!
Saturday 19 November 2016
Elections and the law of large numbers
I know most people have been caught up in the minor and irrelevant issue of the US presidential election $-$ what really mattered in the past couple of weeks was another, much more important election: the ISBA Section on Biostatistics and Pharmaceutical Statistics was renewing many of its officers!
In recent times, I have always been on the losing side of an election (both in Italy and in the UK $-$ although, despite paying my taxes here, I am not allowed to vote in the general elections $-$ and it seemed anywhere there was an election, really...).
Finally, this time around, the spell was broken and I was elected Programme Chair of the section. I have been working in the section for the past two years as secretary, so it'll be nice to continue this process and link even more all the Bayesian activities I'm involved in!
In recent times, I have always been on the losing side of an election (both in Italy and in the UK $-$ although, despite paying my taxes here, I am not allowed to vote in the general elections $-$ and it seemed anywhere there was an election, really...).
Finally, this time around, the spell was broken and I was elected Programme Chair of the section. I have been working in the section for the past two years as secretary, so it'll be nice to continue this process and link even more all the Bayesian activities I'm involved in!
Tuesday 8 November 2016
Lectureship @ UCL

The deadline for application is December 4th and we aim to interview shortly after! Incidentally, working from home should be acceptable...
Saturday 5 November 2016
Always take the weather with you...
Last week, we were in lovely Andalusia $-$ it was Kobi's first half term holiday at school and so we decided to make the most of it. It was actually an awesome week $-$ wonderful weather, nice places and now it's really hard to go back to focus to work...
Anyway, as part of the trip, we went to visit Gibraltar, which is technically a bit of Britain enclosed within Spanish territory. Guess which bit is which...

Anyway, as part of the trip, we went to visit Gibraltar, which is technically a bit of Britain enclosed within Spanish territory. Guess which bit is which...

Monday 10 October 2016
Masters of some

We're updating the promotional material (which will also feature a rather embarrassing interview that I and others have filmed to describe the life-changing advantages people will experience if they come and study with us), so I'll point to more (hilarious, but hopefully also helpful) bits as they become available.
In the meantime, we thought we'd include some ideas of what the syllabus might look like, for different students' backgrounds (in brackets the departments/institutes within UCL already providing the module).
Sample module selection for a student with a first degree in Epidemiology or Statistics (or any other quantitative discipline aside from Economics), wishing to take the Decision Science Stream within the degree
1. Health Systems in a Global Context (Institute of Global Health, IGH)
2. Economic Evaluation (IGH)
3. Medical Statistics I (Statistical Science, Stats)
4. Key Principles of Health Economics
5. Introductory Microeconomics
6. Modelling for Decision Science
7. Bayesian Methods in Economic Evaluation
8. Medical Statistics II (Stats)
Sample module selection for a student with a first degree in Economics, wishing to take the Decision Science Stream within the degree
1. Health Policy and Reform (Centre for Philosophy Justice and Health, CPJH)
2. Economic Evaluation (IGH)
3. Medical Statistics I (Stats)
4. Microeconomics for Health
5. Modelling for Decision Science
6. Bayesian Methods in Economic Evaluation
7. Health Economics (Economics, Econ)
8. Urban Health (IGH)
Sample module selection for a student with a first degree in Epidemiology or Statistics (or any other quantitative discipline aside from Economics), wishing to take the Economic Stream within the degree
1. Health Systems in a Global Context (IGH)
2. Introductory Microeconomics
3. Econometrics (NEW)
4. Economic Evaluation (IGH)
5. Microeconomics for Health
6. Health Economics (Econ)
7. Medical Statistics I (Stats)
8. Bayesian Methods in Economic Evaluation
Sample module selection for a student with a first degree in Economics, wishing to take the Economics Stream within the degree
1. Health Policy and Reform (CPJH)
2. Econometrics (NEW)
3. Economic Evaluation (IGH)
4. Microeconomics for Health
5. Health Economics (Econ)
6. Modelling for Decision Science (NEW)
7. Bayesian Methods in Economic Evaluation
8. Social Determinants of Health
We've already received some applications, which is super good news $-$ but there's still plenty of room!
Friday 7 October 2016
Shiny happy people in the land of the Czar

There's a bunch of us in the department doing work on R and producing packages and so we thought it'd be a good idea to disseminate our research. Which is just as well, as I've been nominated "2020 REF Impact Czar", meaning I'll have to help collate all the evidence that our work does have an impact on the "real world"...
Anyway, after some teething problems (mainly due to my getting familiar with the system and the remote installation of R and Shiny), I think we've now managed to successfully "deploy" (I think that's the correct technical term) two webapps.
These are bmetaweb and BCEAweb. The first one is the web-interface to our bmeta package for Bayesian meta-analysis (which I developed with my PhD student Christina). The main point of bmeta is to allow some sort of standardised framework for a set of models for meta-analysis, depending on the nature of the outcome and some modelling assumption (eg fixed vs random effects). In addition to running the default models (which are based on rather vague priors and pre-defined model structures), bmeta saves data and model code (in JAGS), so that people can actually use these templates and actually modify them to their specific needs.
BCEAweb is the actual mother of the whole project (much as SAVI is then the actual grandmother, as it inspired our work on developing web-interfaces to R packages) and the idea is to use remotely BCEA to post-process the outcome of a (Bayesian) health economic model. BCEAweb works by uploading the simulations from a model and then using remotely R to produce all the relevant output for the reporting of the results in terms of cost-effectiveness analysis.
One thing we've tried very hard to include in both the webapps is the possibility of downloading a full report (in .pdf or .docx format) with a summary of the analyses. I think this is really cool and we'll probably develop more of these $-$ particularly for our work related to statistical methods for health economic evaluations.
Comments welcome, of course!
Thursday 15 September 2016
The fix

I'm writing this post mostly as a signpost for myself $-$ I guess you always encounter issues like this, which seem trivial, and the fix is so easy $-$ if only you had a bunch of little workers at your disposal all the time...
LGM 2016

I couldn't stay for the whole three days, which is a shame because yesterday was really interesting. In the morning, Mike Betancourt (I'm not sure the page I'm linking here is his "official" one, as he's left UCL now) gave an excellent tutorial on Stan. I really enjoyed the morning playing around with the code $-$ in fact, I think we'll try and use it more and more (for example, I will try and integrate this into survHE).
Then in the afternoon, there were two interesting sessions, on talks that had obviously the common thread of LGMs, but were in fact quite diverse. I liked that too!
Tuesday 13 September 2016
Careful whisper

ABSTRACT: A grumpy man vents about spam emails from random scientific (and sometimes pseudo-scientific) journals.
RELEVANCE OF GEORGE MICHAEL'S PICTURE: Virtually none.
MAIN TEXT: First off, I should say that, luckily, my spam filter works pretty well, so I normally don't really get to see these messages (except for when I take 5 minutes to check what's ended up in the spam $-$ typically these are my 5 minutes of fun...).
But, I find it super-hilarious to read the weird invitations to contribute papers to the most bizarre journals (that is bizarre with respect to my own field of expertise, of course $-$ they are often good journals, although I think that sometimes the weirdness goes hand in hand with their ridiculousness...).
Anyway, I particularly really, really like when they start the email with something like this:
Dear Dr Gianluca@my email address, [of course, to these people my email address is my full name]
We follow very carefully your research and we are impressed by your scientific production. We would be delighted if you could contribute a paper (possibly within the next 20 minutes) to the Journal of Something that has absolutely nothing to do with Statistics, or Health Economics, or anything you've ever done in your life since you were 4 and accidentally sat on your mum's little cactus and all the spiny stems pricked your bottom. [and that, sadly, is a true story...]Now, that's what I call carefully following somebody's research!
CONCLUSIONS: Incidentally, one of my biggest regrets in life is to have never managed to wear my hair like George Michael. And that's something I've carefully tried to do when I was 14.
Friday 26 August 2016
Sad night
I've just heard the very sad news that Richard Nixon has passed away this morning. I can't say I knew Richard very well, but I thought he really was a lovely guy and I am very saddened.
I knew of him (among other things) through his work on covariate adjustment in health economic evaluations, which I think was part of his PhD at the MRC Cambridge. I then got in contact with him more closely when I was thinking of organising the short course based on BMHE, since he and Chris were already doing something like that. I suggested we did the course together and he was very enthusiastic about it. In fact, when he was asked to teach a short course at the University of Alberta, he said the three of us should have a go, which we did. Then we taught the course at Bayes 2014, UCL and at a one-day workshop organised by the RSS. He fell ill just before the last edition of the course.
Tonight I have a very vivid memory of the time we were in Edmonton having dinner after the first night of the course when I told that for some reason Italians usually get really crossed about chicken in pizza and that he used to tease me with that every time we've met since, saying that he would love a pizza with chicken. And how we used to introduce ourselves to the audience $-$ and how sometimes people were to young to get the references. I'll miss you, Richard.

I knew of him (among other things) through his work on covariate adjustment in health economic evaluations, which I think was part of his PhD at the MRC Cambridge. I then got in contact with him more closely when I was thinking of organising the short course based on BMHE, since he and Chris were already doing something like that. I suggested we did the course together and he was very enthusiastic about it. In fact, when he was asked to teach a short course at the University of Alberta, he said the three of us should have a go, which we did. Then we taught the course at Bayes 2014, UCL and at a one-day workshop organised by the RSS. He fell ill just before the last edition of the course.
Tonight I have a very vivid memory of the time we were in Edmonton having dinner after the first night of the course when I told that for some reason Italians usually get really crossed about chicken in pizza and that he used to tease me with that every time we've met since, saying that he would love a pizza with chicken. And how we used to introduce ourselves to the audience $-$ and how sometimes people were to young to get the references. I'll miss you, Richard.

Wednesday 17 August 2016
National lottery

As far as I can see, the atlas uses data from a variety of sources (including the Quality Outcomes Framework, QOF, scheme, which collects information from general practices around the country, providing incentives to the doctors to record data on key indicators).
So far so good $-$ nothing wrong with that. In fact, cool representation with maps highlighting geographical variation across England and providing rates for several summary statistics, eg prevalence of dementia, level of diagnosis, etc. As usual, though, the media couldn't resist jumping on the news and making a meal of it, mostly by presenting it with grand headlines, which in many cases missed the point, or bluntly mis-represented reality, I think.
For example, beloved Daily Mail and The Telegraph yell about "Post-code lottery in care". Now, it may well be that the data reveal massive inequality in the access to care and diagnosis across the country, which is a very good thing to expose in order to tackle it and then remove it or at least limit it $-$ that's in the spirit of the NHS. But, although I think the website should have made a much better job at explaining the numbers reported, it appears that the information presented in the maps is about the raw rates! It's not quite clear then whether the background characteristics of each area (defined in terms of Clinical Commissioning Group, CCG) do play a role in explaining away some of the differences in the actual rates for each of the measures reported in the table.
So may well be that we're playing Peter Griffin's lottery with people's health. Or there may be much more than that. But some media just don't care about which is which...
Friday 15 July 2016
Finish line (nearly)

This has been a rather long journey, but I think the current version (I dread using the word "final" just yet...) is very good, I think. We've managed to respond to all the reviewers' comments, which to be fair were rather helpful and so this should have improved the book.
Anna and Andrea have done very good work and I didn't even have to play the bad, control freak guy to have them prepare their bits quickly $-$ in fact, I think at several points, I've been late in doing mine...
Here's the (somewhat simplified to only sections and sub-sections) table of content:
- Bayesian analysis in health economics
- Introduction
- Bayesian inference and computation
- Basics of health economic evaluation
- Doing Bayesian analysis and health economic evaluation in R
- Case studies
- Introduction
- Preliminiaries: computer configuration
- Vaccine
- Smoking cessation
- BCEA - a R package for Bayesian Cost-Effectiveness Analysis
- Introduction
- Economic analysis: the bcea function
- Basic health economic evaluation: the summary command
- Cost-effectiveness plane
- Expected Incremental Benefit
- Contour plots
- Health economic evaluation for multiple comparators and the efficiency frontier
- Probabilistic Sensitivity Analysis using BCEA
- Introduction
- Probabilistic sensitivity analysis for parameter uncertainty
- Value of information analysis
- PSA applied to model assumptions and structural uncertainty
- BCEAweb: a user-friendly web-app to use BCEA
- Introduction
- BCEAweb: a user-friendly web-app to use BCEA
Throughout the book we use a couple of examples of full Bayesian modelling and the relevant R code to run the analysis and then use BCEA to do the "final part" of the cost-effectiveness analysis.
We've tried to avoid unnecessary complications in terms of maths, but we do include explanations and formulae when necessary. It was difficult to strike a balance for the audience $-$ especially as it was complicated to define what the audience would be... I think we're aiming for statisticians who want to get to work in health economic evaluations and health economists who need to use more principled statistical methods and software (I couldn't resist in several points moving my tanks to invade Excelland and replace the local government with R officials...).
The final chapter also present and discuss the use of graphical front-ends to R-based models (eg as in SAVI) $-$ we have a BCEA front-end too. I think these may be helpful, but they can't replace making people in the "industry" more familiar with full modelling and away from spreadsheets and stuff (these work when the models are simple. But the models that are required are not very often that simple...).
We also present lots of work on value of information (including our recent work), which is also linked to our short course. May be it's time to link BMHE and this to do a long course... (there's more on this to come!)
Wednesday 6 July 2016
Bad medical journal
This is an interesting story, I think and I have to say I'm sort of being inspired in the title of the post from a talk that Stephen Senn gave a while back at UCL. He in turn had been referring to Ben Goldacre's book Bad Pharma $-$ the book argues that the pharmaceutical industry is often guilty of cherry picking the evidence they use to substantiate claims of clinical benefits for their product, while Stephen counters that this is rather a two-way street and often respectable medical journals are just as bad.
So: a while back we have done some work on a paper analysing an intervention to facilitate early diagnose of dementia and then submitted it to one of the leading medical journals. Unfortunately, the intervention didn't turn out to produce a massive difference, but we thought it would be interesting anyway. The paper went out for review $-$ in fact it was assessed by 3 reviewers. As per the journal policy, the reviewers have to state their name explicitly, so that the whole process becomes more transparent.
Now, interestingly, the 3 reviewers' comments were (I am copying their comment verbatim, but add my own text in italics below):
So: a while back we have done some work on a paper analysing an intervention to facilitate early diagnose of dementia and then submitted it to one of the leading medical journals. Unfortunately, the intervention didn't turn out to produce a massive difference, but we thought it would be interesting anyway. The paper went out for review $-$ in fact it was assessed by 3 reviewers. As per the journal policy, the reviewers have to state their name explicitly, so that the whole process becomes more transparent.
Now, interestingly, the 3 reviewers' comments were (I am copying their comment verbatim, but add my own text in italics below):
- The authors report a well-designed and well-conducted cluster RCT which addresses a subject of high clinical importance. The findings are conclusively negative in terms of their simple informational intervention effecting earlier diagnosis. This is however an important and clinically useful negative finding, in that it demonstrates that a very simple intervention is not effective in enhancing timely diagnosis. This means that a more multifaceted approach may be needed to address the clinical and policy priority for earlier ab d better diagnosis of dementia. The change in ascertainment of primary outcome to include an imputed MMSE score from ACE data was necessary in the light of unpredicted change in clinical practice due to the prospect of incurring a charge from the copyright holders. The method used is scientifically reasonable and will not have obscured the results of the intervention. This is a good strong paper with an important negative finding that warrants publication.
- THE MANUSCRIPT: [title of the paper] is very important and of high standard.I cecommend [sic] the publication in [name of the journal] without restriction.
- This is a cluster randomized controlled trial of a simple intervention meant to empower patients and their families to seek early assessment for memory difficulties from their primary care physicians. The intervention which included an information leaflet and personalized physician letter was laudably developed with input from patients and caregivers. The experimental design was quite rigorous and utilized an appropriate sample size calculation. One might argue about the choice of the primary outcome measure and whether the intervention as designed could reasonably have been hypothesized to have families bring their relative to EARLIER attention or not (as opposed to bringing them at all), but all outcomes were clearly described and reported. Unfortunately, the study was largely negative. Besides the potential reasons suggested by the authors, not enough attention is paid to primary care physician attitudes to the value, or lack thereof, of an early diagnosis of a memory disorder, when there is a widely perceived lack of effective therapies. Until effective therapies are available, or until physicians can be convinced of the reasons why an earlier diagnosis is advantageous, earlier GP referral to a memory service is unlikely to occur even in the context of a highly empowered patient population.
I think one could argue that reviewer number 3 (remember, in the spirit of the open and transparent policy of the journal, the reviewer is named) is perhaps less enthusiastic than the other two. But I think I would be very happy to receive these sort of review for any paper I ever submit to a journal. And that you'd expect a request for changes to the manuscript (to be fair, reviewer 1 had some minor comments requesting clarification in a couple of parts in the text) but full consideration for publication, at this stage.
Well, that's not quite what happened, because the research editors overruled the reviewers and rejected the paper straightaway. Now, obviously, it is perfectly possible that the editors find flaws in the reviews (although I think you'd question the choice of reviewers, if all 3 turned out to be not up for the job, in the view of the editors who have appointed them...). But I think that their comments were rather out of place $-$ for example, they mention a "8 year difference between Intervention and Control groups", while actually the difference in age was less than a year (and they got confused with an 8 point difference in % of males).
I don't want to sound petty and, as I said, the journal have all the rights to reject the paper $-$ after all, we did acknowledge some of the limitations (e.g. we had important issue with missing data and we dealt with it using statistical methods $-$ interestingly, that wasn't a problem for the editors per se, although they said they thought we had "changed our primary outcome", while we simply imputed missing values for the primary outcome using, among other variables, a similar outcome variable, as mentioned by reviewer number 1). So I think it would have been OK to be told that, because of the issue with missing data, the results did not look strong enough. In fact, we did acknowledge the uncertainty in our estimation, but even after modelling missingness the results were negative, so I think that should have been less of an issue.
Anyway, we did appeal (more to make a point than in hope of any real change) and yet again I was on the losing side $-$ I'm starting to think I should probably start supporting all the causes that I really do not believe in, so that I'll either win some of the future referenda to create as many city-states are there are in the world, or at least will see them fail and take some credit for my personal jinx...
Tuesday 5 July 2016
Fire and mouse alarm

The morning was the most technical part (as intended), but I think everybody was able to follow the talks (which at times had lots of statistical details), because they all had some practical results and nice graphical displays.
The "industry" session was also very interesting and quite varied with different perspectives and problems being highlighted.
Then, just after the start of the final session (which had speakers from NICE and the JCVI, to present the reimbursement agencies perspective), all hell broke lose: first, the fire alarm went off, for what turned out to be basically nothing $-$ I was trying to listen to the conversation between the UCL people and Fire Marshals trying to determine whether there really was a risk and I think I understood that they were getting really annoyed at the alarm going off for what was clearly nothing).
Then, as we resumed the session, we had another interesting surprise. Shortly after the beginning of the second talk, a little mouse (probably disturbed by all the fuss caused by the fire alarm) decided to start roaming through the lecture theatre. I thought I caught a glimpse of something moving suspiciously while I was listening to the talk, but I made nothing of it $-$ until I saw other people looking away from the lectern and increasingly slightly disgusted... Eventually, the mouse got bored (and possibly scared) of the people and disappeared somewhere in one of the air conditioning holes. But that's Central London for you...
Thursday 30 June 2016
Silver lining
Fivethirtyeight has just published their first prediction for the next US presidential election, stating that Clinton has around 80% chance of winning to Trumps' 20%. This has been also reported in the general media (for example here).
I think the tone of the Guardian's article is kind of interesting $-$ basically if first praises Nate Silver's ability but also points out a series of "high-profile misses that could lead some observers to discount their predictions this year". Author Tom McCarthy goes on to report on very wrong predictions for example on Trump's chance of securing the Republican nomination.
I guess this is such a fluid and dynamic situation that perhaps it's a bit too early to call a definitive outcome. But I'm sure we'll be bombarded with predictions in the next few months...
I think the tone of the Guardian's article is kind of interesting $-$ basically if first praises Nate Silver's ability but also points out a series of "high-profile misses that could lead some observers to discount their predictions this year". Author Tom McCarthy goes on to report on very wrong predictions for example on Trump's chance of securing the Republican nomination.
I guess this is such a fluid and dynamic situation that perhaps it's a bit too early to call a definitive outcome. But I'm sure we'll be bombarded with predictions in the next few months...
Friday 17 June 2016
Workshop on Infectious Disease Modelling in Public Health Policy: Current status and challenges (yet, again)
I've written about this a couple of times already (here and here). We've finalised the speakers line up (see here for the latest information) and I think this is a very exciting programme! (I know you may think "well, he would say that, wouldn't he?" $-$ and you're probably right... But I do think that the line up is really interesting!).
Anyway, although the registration list on Eventbrite is formally close, I think we do have some places available $-$ so if you would like to go, send me an email (details on the website)!
Anyway, although the registration list on Eventbrite is formally close, I think we do have some places available $-$ so if you would like to go, send me an email (details on the website)!
My week at ISBA (2)
I should add to my previous post that while there have been many very good talks, I thought two were incredibly good: David Spiegelhalter's Foundational lecture on Monday and Adrian Raftery's talk in a session on Bayesian Demography that was very interesting overall. I'm not sure whether slides will be made available, but if they are, you should definitely check them out!
In particular, Adrian's talk was about the application of Bayesian hierarchical methods to formally account for and quantify uncertainty in population projections (I think this is the relevant paper). He started his talk by showing a screenshot from the BBC website reporting on Boris Johnson's claim that if the UK stays within the EU, its population will "increase to 80 millions" (from the current level of around 65 millions).
As Adrian pointed out, it wasn't clear what time frame was Johnson referring to. However, I'd say unsurprisingly, his model showed that this event had virtually no chance of happening within the next 5 years and at most around 40% chance of happening in a period of 25 years [I am citing the numbers by memory, so the details may be slightly different, although they are most definitely in the right ball-park!].
In particular, Adrian's talk was about the application of Bayesian hierarchical methods to formally account for and quantify uncertainty in population projections (I think this is the relevant paper). He started his talk by showing a screenshot from the BBC website reporting on Boris Johnson's claim that if the UK stays within the EU, its population will "increase to 80 millions" (from the current level of around 65 millions).
As Adrian pointed out, it wasn't clear what time frame was Johnson referring to. However, I'd say unsurprisingly, his model showed that this event had virtually no chance of happening within the next 5 years and at most around 40% chance of happening in a period of 25 years [I am citing the numbers by memory, so the details may be slightly different, although they are most definitely in the right ball-park!].
My week at ISBA
I've spent the last few days in beautiful Sardinia for the ISBA world conference. The place is outstanding, really beautiful, although it's kind of weird that there is no real town along the cost for miles and miles. Leaving Cagliari and driving for over 50km, you only come across a massive oil refinery and the town of Pula. There are many resorts (some super high-end, like the one where the conference is, some more like very nice camping sites with tents or bungalows replaced by nice apartments), but no real town. I felt that was a bit weird as I wasn't used to things like that, in Italy $-$ but it may well be that I am just ignorant about my own country and there's tons of places like that...
As for the conference, my last ISBA was 10 years ago $-$ that was the last one of the original "Valencia meetings". Even then, it felt like a big conference, but that was nowhere near the level it has reached now (I think there are over 700 people here!). This means there are several parallel sessions and lots of heterogeneity in the topics. Also, the schedule is quite packed with talks from 9am to 7.30pm (with some breaks throughout) and then poster sessions after dinner. I was impressed by how well the organisation has worked: I've not seen a single session running late!
My talk is later today; I'll be talking about our work on the RDD $-$ I've planned a rather high-level talk, showing some of the general themes we've developed and giving broad examples, rather than going to the details. Luckily, we do have a few papers on these so hopefully I'll be able to point people to the relevant references.
More importantly, I'll have to rush off just after my talk (which isn't great) so that I won't miss my flight home $-$ I've tried to plan everything ahead, so I've put petrol in the car, checked out the hotel, etc. I'll give the talk with my fingers crossed, just in case...
As for the conference, my last ISBA was 10 years ago $-$ that was the last one of the original "Valencia meetings". Even then, it felt like a big conference, but that was nowhere near the level it has reached now (I think there are over 700 people here!). This means there are several parallel sessions and lots of heterogeneity in the topics. Also, the schedule is quite packed with talks from 9am to 7.30pm (with some breaks throughout) and then poster sessions after dinner. I was impressed by how well the organisation has worked: I've not seen a single session running late!
My talk is later today; I'll be talking about our work on the RDD $-$ I've planned a rather high-level talk, showing some of the general themes we've developed and giving broad examples, rather than going to the details. Luckily, we do have a few papers on these so hopefully I'll be able to point people to the relevant references.
More importantly, I'll have to rush off just after my talk (which isn't great) so that I won't miss my flight home $-$ I've tried to plan everything ahead, so I've put petrol in the car, checked out the hotel, etc. I'll give the talk with my fingers crossed, just in case...
Friday 3 June 2016
Large enough probability?

However, I was talking earlier to my "polls guy" Roberto (yes: I have a polls guy) and he's suggested I took a look at Stephen Fisher's blog, who is predicting a 72% chance that the outcome of the referendum will be "remain" (in the EU). I think I'll take that as a good sign.
In the past couple of days, people have put forward the argument that the UK should take their economy back and "do like New Zealand in the 1980s $-$ that was very good for their economy, so surely it'll work for us too". [start rather annoyed irony]Surely the global economy and trading system were exactly what they are today, back in the 1980s, so surely this is super relevant evidence and something we should be basing our judgement on, today...[end rather annoyed irony]
Monday 23 May 2016
Bayes 2016

As for the more statsy-bits of the conference, as usual I really enjoyed it very much $-$ we always try to make a point of getting talks of high methodological level from both academia and industry, which in my opinion makes for a very nice three days!
In addition, the social part of being at Bayes 20XX is also usually very attractive $-$ and this year has not disappointed. At the end of the first day of the conference, we had a beer-tasting tour $-$ as Emmanuel put it, that was really a study to find the maximum tolerated dose: we were there to determine at what point in the escalation of the beer alcohol percentage we would seriously need to stop (we passed 5% without problems, then worked our way to an 8% and then had to go for dinner after a 10%)...
Anyway, I think the programme was packed with very interesting talks and hopefully, we'll be soon able to upload the presentations! And next year we'll go to Albacete, where Virgilio will play host. In keeping with our grand tradition, several people have been ambushed and as a consequence we do have quite a few candidates to host the next edition in 2018...
Sunday 22 May 2016
BCEA 2.2-3 is out
I think the newest release of BCEA, our R package to standardise and post-process the output of a health economic model, is now available from CRAN $-$ in fact, the source code is also available here. The package is rather stable, so the changes aren't many, but the few ones are quite substantial, I think. In particular, we've now modified the function evppi, which is used to perform the analysis of the expected value of partial information (incidentally, that's also related to our upcoming short course).
In the last few years this has been a very interesting and fertile area of research within the health economics community, with interesting methods being proposed $-$ this is a nice editorial by Nicky Welton and Howard Thom, while this is (an arxived version of) our own technical review.
BCEA implements all the most recent methods, with particular focus on Strong et al's based on Gaussian Process regression and our own work (just published in Statistics in Medicine), which, building on their work, uses INLA to speed up the computation even further. In addition, we have also included a graphical tool that can be used to describe, at least as a first order approximation, the individual impact of each parameter on the overall uncertainty in the decision-making process. We have called this the info-rank plot, which is basically a generalisation of commonly used (especially when economic evaluations are performed under a frequentist approach) Tornado plots. The info-rank is based on the single-parameter EVPPI and can be used to roughly determine the contribution of each single parameters to the overall value of partial information (of course, because the EVPPI is a highly non-linear function, combinations of parameters are not additive, so some caution is needed here).
In the last few years this has been a very interesting and fertile area of research within the health economics community, with interesting methods being proposed $-$ this is a nice editorial by Nicky Welton and Howard Thom, while this is (an arxived version of) our own technical review.
BCEA implements all the most recent methods, with particular focus on Strong et al's based on Gaussian Process regression and our own work (just published in Statistics in Medicine), which, building on their work, uses INLA to speed up the computation even further. In addition, we have also included a graphical tool that can be used to describe, at least as a first order approximation, the individual impact of each parameter on the overall uncertainty in the decision-making process. We have called this the info-rank plot, which is basically a generalisation of commonly used (especially when economic evaluations are performed under a frequentist approach) Tornado plots. The info-rank is based on the single-parameter EVPPI and can be used to roughly determine the contribution of each single parameters to the overall value of partial information (of course, because the EVPPI is a highly non-linear function, combinations of parameters are not additive, so some caution is needed here).
Monday 9 May 2016
How to be Bayesian and spare yourself a dreadful afternoon with your stupid football team losing the derby
Yesterday was the second-last game of the Italian Serie A; I've been a Sampdoria supported since I was 12 $-$ at that time, they were starting to become one of the best clubs in Serie A (and that was back in the 80's when Serie A was arguably the best league in the world), although they hadn't won anything and didn't have prospects for that season either. But they were a young, good side, playing nicely and so I kind of fell in love with them (and their shirt). Then they did become a very good side, winning the league and a few more trophies $-$ so good timing on my part! But also, then they reverted to some relative mediocrity $-$ of course, once you've decided you support a team, you're stuck with them no matter what.
Anyway, this season has been rather crappy and yesterday it was a crucial game: we were playing the derby against local rival Genoa entering the game with 40 points and two games left in the campaign. Two teams couldn't reach us any more (as they were trailing by over 6 points). But at least one between Carpi and Palermo could still overtake us if we lost our two remaining games and they won all of theirs. Also, Udinese was just one point behind us so they too could overtake us, technically. With three teams being relegated, we weren't statistically safe yet.
So, that's kind of nervous and earlier last week I thought about this a bit. I had a bad feeling about our game, because we've not been great lately (the previous game we were beaten by Palermo) and, clearly, Genoa would try really hard to mess it up for us... But, irrespective of the outcome of the derby, if at least one between Carpi, Palermo and Udinese failed to win their match we would be safe (as there wouldn't be enough points left for them to catch us). Carpi played at home against Lazio, whose season hasn't been great either, but they were already safe and with not much else to fight for, except a strong finish; Palermo were away at Fiorentina, who theoretically were still fighting for a Europa league qualification and so should have something to play for; Udinese were away at Atalanta, who much as Lazio were mathematically safe and with not much to play for.
Although one can make a much more complex model, I reasoned that instead of the actual result, what was only important was the chance that either of the three teams behind us would win and so I set up a model with $ y_{\rm{Car}} \sim \mbox{Bernoulli}(\theta_{\rm{Car}})$, $y_{\rm{Pal}} \sim \mbox{Bernoulli}(\theta_{\rm{Pal}})$ and $y_{\rm{Udi}} \sim \mbox{Bernoulli}(\theta_{\rm{Udi}})$ where the "success" would in fact be the worst possible outcome, ie a win for them.
Then I set up some priors: I reasoned that because they were playing at home, Carpi may have a slightly higher chance of winning the game $-$ I figured something about 35%. Also, I thought (hoped) that Lazio wouldn't be a walkover and so I assumed that 90% of the mass for the chance of Carpi winning their game was around 45%. These can be turned into an informative Beta(15.80107,28.4877) prior $-$ it's fairly easy to work out the parameters of a Beta distribution given the mode (0.35, in this case) and some percentile (0.45 as the 90th percentile, in this case); Christensen et al (page 100) show some theory, while this is some relevant R code.
This is effectively the prior I was assuming:



Anyway, this season has been rather crappy and yesterday it was a crucial game: we were playing the derby against local rival Genoa entering the game with 40 points and two games left in the campaign. Two teams couldn't reach us any more (as they were trailing by over 6 points). But at least one between Carpi and Palermo could still overtake us if we lost our two remaining games and they won all of theirs. Also, Udinese was just one point behind us so they too could overtake us, technically. With three teams being relegated, we weren't statistically safe yet.
So, that's kind of nervous and earlier last week I thought about this a bit. I had a bad feeling about our game, because we've not been great lately (the previous game we were beaten by Palermo) and, clearly, Genoa would try really hard to mess it up for us... But, irrespective of the outcome of the derby, if at least one between Carpi, Palermo and Udinese failed to win their match we would be safe (as there wouldn't be enough points left for them to catch us). Carpi played at home against Lazio, whose season hasn't been great either, but they were already safe and with not much else to fight for, except a strong finish; Palermo were away at Fiorentina, who theoretically were still fighting for a Europa league qualification and so should have something to play for; Udinese were away at Atalanta, who much as Lazio were mathematically safe and with not much to play for.
Although one can make a much more complex model, I reasoned that instead of the actual result, what was only important was the chance that either of the three teams behind us would win and so I set up a model with $ y_{\rm{Car}} \sim \mbox{Bernoulli}(\theta_{\rm{Car}})$, $y_{\rm{Pal}} \sim \mbox{Bernoulli}(\theta_{\rm{Pal}})$ and $y_{\rm{Udi}} \sim \mbox{Bernoulli}(\theta_{\rm{Udi}})$ where the "success" would in fact be the worst possible outcome, ie a win for them.
Then I set up some priors: I reasoned that because they were playing at home, Carpi may have a slightly higher chance of winning the game $-$ I figured something about 35%. Also, I thought (hoped) that Lazio wouldn't be a walkover and so I assumed that 90% of the mass for the chance of Carpi winning their game was around 45%. These can be turned into an informative Beta(15.80107,28.4877) prior $-$ it's fairly easy to work out the parameters of a Beta distribution given the mode (0.35, in this case) and some percentile (0.45 as the 90th percentile, in this case); Christensen et al (page 100) show some theory, while this is some relevant R code.
This is effectively the prior I was assuming:

and I thought it was just about reasonable (the dotted vertical lines indicate a rough estimate of the 95% prior credible interval). Then I did something similar to derive the priors for a Palermo and Udinese win $-$ because they were playing away, I figured they would have an average chance of winning of around 20% with 90% of the mass before 40%, which can be turned into a Beta(3.279775,10.1191) prior, looking like this:

Again, I was relatively happy with this and so used these priors in my model, which one could code in R as something like
p.car ~ rbeta(10000,15.80107,28.4877) # P(win) on average .35 and with 95% mass <= .45
p.pal ~ rbeta(10000,3.279775,10.1191) # P(win) on average .2 and with 95% mass <=.4
p.udi ~ rbeta(10000,3.279775,10.1191) # P(win) on average .2 and with 95% mass <=.4
p.safe <- 1-(p.car*p.pal*p.udi)
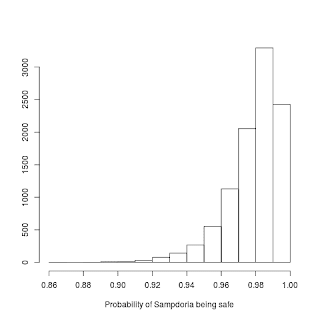
The most important variable in the model is the probability of Sampdoria being mathematically certain of avoiding relegation, p.safe, which is 1 minus the probability of the worst happening $-$ this assumes independence in the three games for Palermo, Carpi and Udinese; in general that's probably not the best assumption, but in this case they kind of had to win to have a good shot at safety themselves and so I think it's OK to assume independence. The results were kind of reassuring:

$-$ I got an estimated posterior average of 97.8% with a 95% credible interval of 93.8 to 99.7%.
I am not really one to stay at home on a Sunday just to watch the football game (so perhaps I'm not really a footaball fan?) and we'd planned to see some friends, but this reassured me that we shouldn't be in too much trouble, even if we lost the derby. In the event, Kobi wasn't great (possibly as a result of venturing an outing at the seaside on Saturday) and so we stayed at home $-$ but I decided not to bother with watching the game (again: a) a bold move for a real football fan, confident about his team; b) a cowardly move from a real football fan scared of what the outcome may be; c) not a real football fan).
We did lose the derby very badly, but Carpi, Palermo and Udinese all failed to win their games, which means we are safe. I'm glad I didn't watch the game...
Thursday 21 April 2016
Workshop on Infectious Disease Modelling in Public Health Policy: Current status and challenges (again)
We've had a fantastic response to the workshop. In just a few days of public advertisement (I firstly posted about it and then advertised on allstat and HEALTHECON-ALL) we got 65 registration, as of today.
We have provisionally set out 100 "tickets" (although the workshop is free). I think we may be able to actually extend this a little and have a few more participants. But the main message is this:
Hurry up!
We have provisionally set out 100 "tickets" (although the workshop is free). I think we may be able to actually extend this a little and have a few more participants. But the main message is this:
Hurry up!
Wednesday 13 April 2016
Workshop on Infectious Disease Modelling in Public Health Policy: Current status and challenges
Later this year, we're holding at UCL a workshop on modelling for infectious disease with specific focus on the implications and challenges for health economic evaluation.
I think this is a very interesting area for all sorts of different reasons: in particular, modelling is generally complex (because infectious disease need to be modelled accounting for population dynamics and interactions). This may have implications in terms of health economic evaluation, because the extra complexity impacts on the possibility/simplicity with which one can perform full probabilistic sensitivity analyses.
The workshop (which will be on 4th July) will try and explore three different perspectives: in the morning, we'll have a discussion from the methodological point of view; we'll try and explore the established analytic methods and the challenges in adapting them to a full economic assessment (as opposed to an epidemiological perspective, which, I think, is where they are established in the first place).
Then in the afternoon we'll have two sessions exploring the industry and then the regulatory perspectives. Again we'll try and discuss the implications and challenges faced when dealing with interventions against infectious diseases, from a public health decision-making point of view.
More information on the day are available here, while details for registration are here.
I think this is a very interesting area for all sorts of different reasons: in particular, modelling is generally complex (because infectious disease need to be modelled accounting for population dynamics and interactions). This may have implications in terms of health economic evaluation, because the extra complexity impacts on the possibility/simplicity with which one can perform full probabilistic sensitivity analyses.
The workshop (which will be on 4th July) will try and explore three different perspectives: in the morning, we'll have a discussion from the methodological point of view; we'll try and explore the established analytic methods and the challenges in adapting them to a full economic assessment (as opposed to an epidemiological perspective, which, I think, is where they are established in the first place).
Then in the afternoon we'll have two sessions exploring the industry and then the regulatory perspectives. Again we'll try and discuss the implications and challenges faced when dealing with interventions against infectious diseases, from a public health decision-making point of view.
More information on the day are available here, while details for registration are here.
Tuesday 12 April 2016
The internship

Mapi and us (as in UCL/Stats Science) have a very good working relationship $-$ in fact, we do have an ongoing research project which I am leading. I find interaction with them very interesting and helpful $-$ we get to work on "real-life" problems and usually the issues we have to face are very interesting and challenging from the methods point of view.
For example, some of the work on survival analysis in health economics that I have mentioned here has originated by a project I was working on together with colleagues in Mapi's London office.
Anyway, I'm copying the text of the advert below!
Our company is offering a paid 6 month internship for MSc graduates in statistics. This internship is based in Utrecht or London and the candidates must have the right to work in the Netherlands or UK to apply for this role. This is a unique opportunity for an individual with a background in (bio-) statistics to gain experience in the field of health economics and outcomes research. The successful intern will work as a Research Assistant and will report to a Research Manager in our Real World Strategy & Analytics unit. A Research Assistant will be required to undertake the following activities:or
- Evidence synthesis (meta-analysis, indirect treatment comparison, network meta-analysis) - including dataset preparation, analysis, preparation of tables/graphs with results, interpretation, reporting;
We are also open to ideas about small research projects (research focused internship) that could for example lead to a publication. The ideal intern's personality and qualifications:
- Development/adaptation of economic models for decision making – including: VBA programming, analysis, preparation of tables/graphs with results, interpretation, reporting;
- Masters degree or higher in (bio-) statistics (applied mathematics, operational research, economics or relevant are also considered);
- Good knowledge of R (SAS and WinBUGS/OpenBUGS are a plus);
- Fluent in written and spoken English;
- High level of proficiency with Word and Excel;
- High attention to detail;
- Analytical and organised;
Candidates can find more details about our company on our website: http://mapigroup.com. Applications, including a CV and motivation letter, can be sent to talent@mapigroup.com Closing date for applications: May 31st
- Proactive in communication.
Subscribe to:
Posts (Atom)